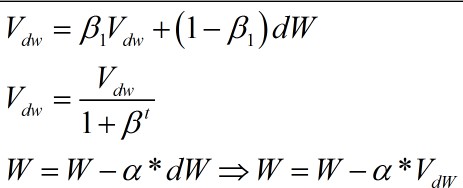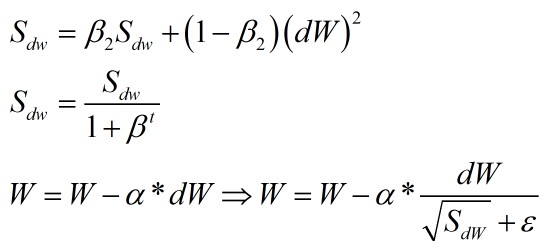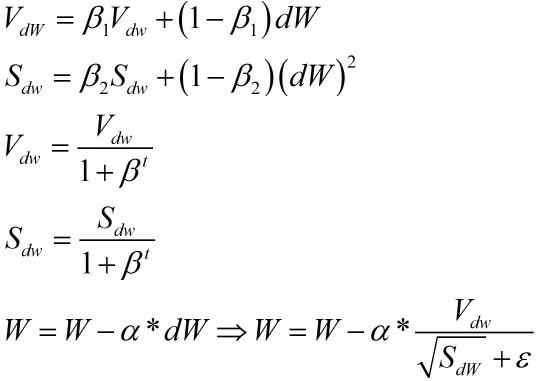这周的课程开始了新的优化算法,优化的主要措施有以下三种:
- Mini-Batch梯度下降算法
- Momentum算法
- RMSprop算法
- Adam算法
Mini-Batch梯度下降算法
此算法与之前的梯度下降算法差别在于数据的迭代方式,梯度下降法直接将整个数据集进行训练,而Mini-Batch梯度下降算法则是根据一定条件将整个数据集进行分割,每个小数据集进行一次梯度下降,其实梯度下降法是MiniBatch算法的一个特例。具体实现的时候,Mini-Batch与梯度下降的主要区别是(1)分割数据集(2)增加数据集的内部循环。与梯度下降差别不大,在这里就不实现了。
partition.png
Momentum算法
Momentum算法与梯度下降算法的差别在于参数W和b的更新。更新的公式变成了下面的公式。
更新公式
也就是说,参数更新时的变化量从dW变成了Vdw,其他的没有很大的变化,其中t为。实现代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| def update_parameters_with_momentum(parameters, grads, v, beta, learning_rate, t):
L = len(parameters) // 2
for l in range(L):
v["dW" + str(l+1)] = beta * v["dW" + str(l + 1)] + (1 - beta) * grads['dW' + str(l + 1)]
v["db" + str(l+1)] = beta * v["db" + str(l + 1)] + (1 - beta) * grads['db' + str(l + 1)]
v_corrected["dW" + str(l+1)] = v["dW" + str(l+1)] / (1 - beta1**t)
v_corrected["db" + str(l+1)] = v["db" + str(l+1)] / (1 - beta1**t)
parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate * v["dW" + str(l+1)]
parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate * v["db" + str(l+1)]
return parameters, v
|
RMSprop算法
RMSprop算法与Momentum算法类似,差别在于更新参数的方式。公式如下;
迭代公式
实现代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def update_parameters_with_momentum(parameters, grads, s, beta, learning_rate, t, epsilon=10e-8):
L = len(parameters) // 2
for l in range(L):
s["dW" + str(l+1)] = beta2 * s["dW" + str(l + 1)] + (1 - beta2) * (grads['dW' + str(l + 1)]**2)
s["db" + str(l+1)] = beta2 * s["db" + str(l + 1)] + (1 - beta2) * (grads['db' + str(l + 1)]**2)
s_corrected["dW" + str(l+1)] = s["dW" + str(l+1)] / (1 - beta2**t)
s_corrected["db" + str(l+1)] = s["db" + str(l+1)] / (1 - beta2**t)
parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate * parameters["W" + str(l+1)] / (np.sqrt(s_corrected["dW" + str(l+1)]) + episilon)
parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate * parameters["b" + str(l+1)] / (np.sqrt(s_corrected["db" + str(l+1)]) + episilon)
return parameters, s
|
Adam算法
Adam算法综合了Momentum算法和RMSprop算法,更新公式如下
迭代公式
实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| def update_parameters_with_adam(parameters, grads, v, s, t, learning_rate = 0.01, beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8):
L = len(parameters) // 2
v_corrected = {}
s_corrected = {}
for l in range(L):
v["dW" + str(l+1)] = beta1 * v["dW" + str(l + 1)] + (1 - beta1) * grads['dW' + str(l + 1)]
v["db" + str(l+1)] = beta1 * v["db" + str(l + 1)] + (1 - beta1) * grads['db' + str(l + 1)]
v_corrected["dW" + str(l+1)] = v["dW" + str(l+1)] / (1 - beta1**t)
v_corrected["db" + str(l+1)] = v["db" + str(l+1)] / (1 - beta1**t)
s["dW" + str(l+1)] = beta2 * s["dW" + str(l + 1)] + (1 - beta2) * (grads['dW' + str(l + 1)]**2)
s["db" + str(l+1)] = beta2 * s["db" + str(l + 1)] + (1 - beta2) * (grads['db' + str(l + 1)]**2)
s_corrected["dW" + str(l+1)] = s["dW" + str(l+1)] / (1 - beta2**t)
s_corrected["db" + str(l+1)] = s["db" + str(l+1)] / (1 - beta2**t)
parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate * v_corrected["dW" + str(l+1)] / (np.sqrt(s_corrected["dW" + str(l+1)]) + epsilon)
parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate * v_corrected["db" + str(l+1)] / (np.sqrt(s_corrected["db" + str(l+1)]) + epsilon)
return parameters, v, s
|
最后更新时间: